
The Incredible Potential of Text Analytics – The Use Cases Explained.
New advances in text analytics make the tech news nearly every week, most prominently IBM Watson, but also more recently AI approaches such as ELMo or BERT. And now it made world news with the pandemic caused by the Covid-19 virus, with the white house requesting help via NLP.
Text Analytics and Natural Language Processing (NLP) deal with all types of automatic processing of texts and is often built on top of machine learning or artificial intelligence approaches. The idea of this article is not to explain how text analytics works, but instead to explain what is possible.
Who are the Stakeholders? What are their Use Cases?
There are basically four main groups interested in the usage of text analytics: People writing text, people trying to read (especially large pieces of) text, people responsible for large chunks of text, either as a supervisor or as a quality advisor, and people using the text as an input for follow-up activities . In a nutshell these four roles can profit from text as follows:
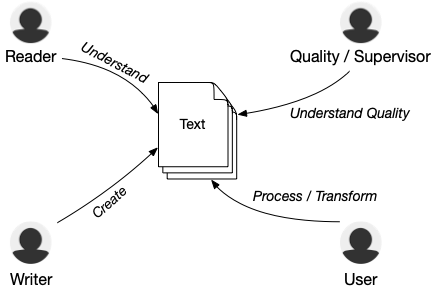
- The Writer: Text Analytics supports text creators immediately and in an unbiased way.
- The Reader: Text Analytics visualizes the invisible.
- The Quality Manager or Supervisor: Text Analytics helps to control the incontrollable.
- The User of the Text: Text Analytics enables to extract the value from the clutter.
In the following, I’ll show which relevant questions Text Analytics can answer for each of those roles.
Use Case 1: Text Analytics Supports Text Creators Immediately and in an Unbiased Way.
For the first use case, imagine you need to write a text. For example, a blog post, a requirement, a test case, a contract, etc etc etc. There are so many different quality aspects that you are probably thinking about. You are (hopefully) asking yourself: Is my text understandable? Is it precise? Is my wording consistent? Did I follow all the company guidelines (e.g. patterns, templates, syntax)? And also: Did I just unintentionally create a new text that someone else already wrote? An automatic Text Analytics approach can give you immediate feedback about the text. And your colleagues can focus on the actual content instead of company guidelines and language issues, as we found out in this study.
For you as a text creator, Text Analytics includes language checks like spell checkers or grammarly, but it can be so much more. You can get automatic feedback not just for generic language quality, but for text quality specifically for a particular document type.
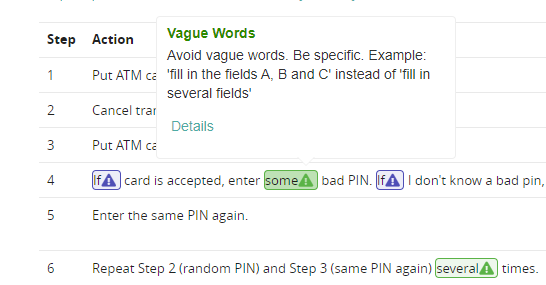
Screenshot: Our Text Analytics suite helps authors writing high quality texts while writing.
But text analytics can support you as a text creator in so much more than just this. For example, text analytics can even help you by artificially creating whole blocks of text. A great example of this is https://talktotransformer.com, which finishes any text given as an input in a character-by-character fashion. In these breathtaking examples, TalkToTransformer is able to create text that are sometimes difficult to distinguish from texts created by humans. Try it yourself here.
Screenshot: TalkToTransformer finishes a piece of text automatically.
Use Case 2: Bring Light to the Invisible for Readers
I am very often concerned with the second use case. It happens that someone sends me a hundred-page document (or larger) and asks for my feedback. Here I quickly need to understand the topics or key terms that the text talks about. Sometimes I search for specific text locations, e.g. which are all the places that talk about my component within the system? However, in the perfect world, I don’t want to read each word, but get a summary of each paragraph: What does this paragraph talk about? For example, when I do requirements audits, I want to know what are all the paragraphs that contain requirements and which parts are just glue text or explanations. And lastly, I often get multiple documents at once. So here I need to know what the relation between the different documents is: How do they relate to each other, how much do they overlap?
You know what’s fantastic: For all of these questions there are existing Text Analytics solutions. For some, like paragraph summarization, it is pretty much bleeding edge research. For others, such as relationships between texts, established algorithms are well understood and also newly existing libraries for getting a more semantic understanding of words are used in hundreds, if not thousands of projects. Here is an example where we worked on a classification of texts into requirements together with the DKE:

Screenshot: In this project we help automatically discovering and tagging requirements in an ISO Standard.
Use Case 3: Controlling the Uncontrollable for Supervisors or Quality Managers
A specific variant of Use Case 2 is to understand the quality of a huge text suite, usually over time. In too many cases, a 200-page text document is like a black hole for supervisors. No one, who knows what’s going on in there, has ever made it back to this world. This is especially dangerous talking about quality. For example, when a company introduces a new training, defines a new guideline or a new review process: How do you see whether people actually follow quality standards or guidelines (like in this case study with MunichRe)? How can you measure whether the texts improve after the new training? And which parts of the documents have not changed in a long time although they probably should have?
Automatic analysis enables you to check many and long documents in their quality development over time. If you are in charge of the quality of these black holes, you can now take over the steering wheel again.
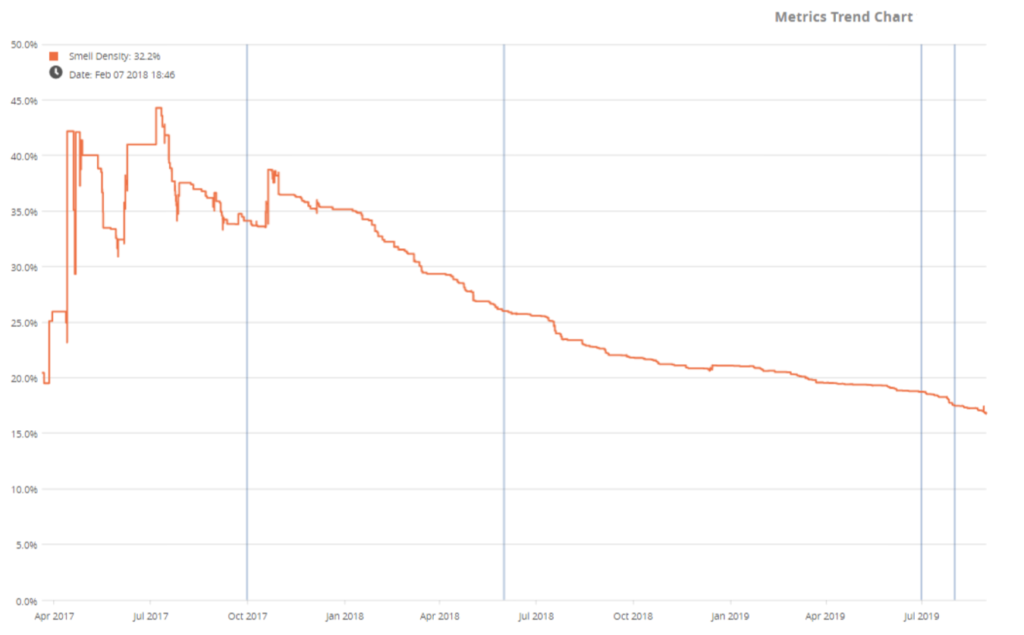
Screenshot: The Qualicen Scout shows a trend analysis of the quality of a test suite from one of our customers. It began with a pretty bad trend (more findings) at the beginning, but it measurably and visibly improved over time after we joined.
Use Case 4: Extracting Value from the Clutter for Text Users
Last not least: Why do you usually read texts? Of course to extract some value, to extract some knowledge and create something new out of that! For example, testers take a requirement, do some magic, and create models and test cases from it (check this blog post for a more detailed explanation). And that is the case for many of your daily tasks. Text Analytics here helps us to extract and use specific information, knowledge, and therefore value from a text. It furthermore enables us to translate text to other languages, into structured representations (e.g. models), or to other text forms, e.g. test cases.
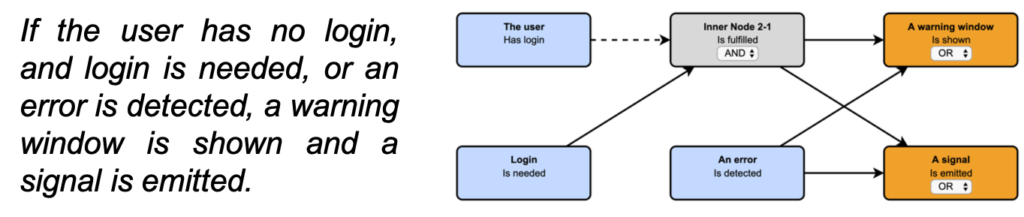
Screenshot: The free open source tool Specmate by Qualicen allows to extract cause-and-effect-graphs from natural language. Once you have these cause-and-effect-graphs you can fully automatically generate test cases!
TL;DR: Text Analytics is Becoming a Powerful Tool.
Wow, those are really more applications than I thought when I started writing this article. Too many to remember. Okay, follow after me:
- The Writer: Text Analytics supports text creators immediately and in an unbiased way.
- The Reader: Text Analytics visualizes the invisible.
- The Quality Responsible or Supervisor: Text Analytics helps to control the uncontrollable.
- The User of the Text: Text Analytics enables to extract the value from the clutter.
So many applications. I probably missed some, so let me know about these in the comments. And since you made it here, I guess you are wondering whether text analytics could work for you? I’d be happy to give you my opinion and also support you with my team. Let me know at henning.femmer@qualicen.de or underneath in the comments!



Sorry, the comment form is closed at this time.
Kathlene
14/06/2020Highly energetic post, I liked that bit. Will there be a part 2?
Henning Femmer
16/06/2020Sure, what would you like me to write about?
Pingback: 3 Ansätze, natürlichsprachige Anforderungen maschinell zu verarbeiten - Systems Engineering Trends
22/10/2020Pingback: 3 Ansätze, natürlichsprachige Anforderungen maschinell zu verarbeiten | Systems Engineering Trends
13/01/2021