Natural Language Processing: Timeline Extraction with Regexes and spaCy
New text is generated in a mindblowing speed today. Think about news articles, social media messages, reports, e-mails etc. However, we cannot do much with unstructured text. But as soon as we extract some structured information from it, we can use it to run analyses, to make predictions, to inform decisions etc.
In this blog post, we show how to use natural language processing techniques to retrieve information from unstructured text automatically. In a first attempt we use a simple regular expression to extract events. However, this is cumbersome and rather imprecise. Therefore, in a second attempt, we use spaCy and its Named Entity Recognition and dependency parsing features.
But be warned! This artical is quite technical and dives into details of modern deep learning techniques. If you are just interested in the results, you better jump directly to the TL;DR section. You want to try the code yourself? This article is also available as Google Colab Notebook.
The History of Germany
Often we are interested in finding out if some event happend – and when it happend. For example, from the piece of text On March 1st 2020, Joe Biden wins the South Carolina primary. we want to extract the event [2020/03/01] - [Joe Biden wins the South Carolina primary]
This blog post, we try to generate a timeline that should roughly look like the timeline of german history on wikipedia. Here is an excerpt:
| Date | Event |
|---|---|
| 1338 | The prince-electors of the Holy Roman Empire declared in the Declaration of Rhense that the election of the Holy Roman Emperor was not subject to the approval of the pope. |
| 1356 | The Imperial Diet issued the Golden Bull of 1356, which fixed the offices of the seven prince-electors and established that the Holy Roman Emperor could be elected by a simple majority vote. 1356 |
| 1370 | The Treaty of Stralsund was signed, ending a war between Denmark and the Hanseatic League. |
| 1392 | The Victual Brothers were hired by the Duchy of Mecklenburg to assist in its fight against Denmark. |
| 1400 | The period of Meistersinger lyric poets began. |
| 1400 | The period of Minnesänger singers ended. |
Preparation
Dates and date-ranges come in a lot of different formats. In order to compare dates and to pinpoint them on a timeline, we use dataparser. You can install it with the following command:
pip install daterangeparserRESULT Collecting daterangeparser Downloading https://files.pythonhosted.org/packages/46/0e/67d6a9912b216417d9a4adf2c716ff628a5fc1797fcafd5a7599928622c8/DateRangeParser-1.3.2-py3-none-any.whl Requirement already satisfied: pyparsing in /usr/local/lib/python3.6/dist-packages (from daterangeparser) (2.4.6) Installing collected packages: daterangeparser Successfully installed daterangeparser-1.3.2
We need a couple of imports
import re
import spacy
import requests
import re
import IPython
from daterangeparser import parseObtain Data
This notebook uses the wikipedia article on the history of germany as an example, as it contains a lot of dates and events. In order to avoid complexities such as using the wikipedia API or to remove references, htmls tas etc., we use a version that only contains the main content as text. You can find it here: https://github.com/qualicen/timeline/
response = requests.get('https://raw.githubusercontent.com/qualicen/timeline/master/history_of_germany.txt')
text = response.text
print('Loaded {} lines'.format(text.count('\n')))
RESULT: Loaded 744 lines
First Attempt: Regular Expressions
Our first attempt will be to use regular expressions in order to find events. The difficulty is to come up with a pattern to capture the many ways a date can be written (e.g. “in april 1975” or “in the spring of 1975” etc.). A second difficulty is to identify numbers or expressions where we can be reasonable sure that the number signifies a date and not something else. Look at the following sentence: Charlemagne ended 200 years of Royal Lombard rule with the Siege of Pavia, and in 774 he installed himself as King of the Lombards. There are two numbers (200 and 774) which could be dates, but only one of them is in fact a date.
In fact, this is a quite difficult task to do with regular
expressions. We need to define a lot of patterns to capture the most
common situations. As an example, we could define a pattern like this: In [DATE], [EVENT]. In the example above, this would capture the following event: in 774 he installed himself as King of the Lombards.
The pattern from above is exactly what the following function extracts. We will apply the function on each line of the text to extract events.
def extract_events_regex(line):
matches = []
# capture thee digit and four digit years (1975) and ranges (1975-1976)
found = re.findall('In (\d\d\d\d?[/\–]?\d?\d?\d?\d?),? ?([^\\.]*)', line)
try:
matches = matches + list(map(lambda f: (f[0] if len(f[0])>3 else "0"+f[0] ,f[0],f[1]),found))
except:
return []
return matches
def extract_all_events(text, extract_function):
all_events = []
processed = 0
# Process the events
for processed,line in enumerate(text.splitlines()):
events = extract_function(line)
all_events = all_events + events
if processed % 100 == 0:
print('Processed: {}'.format(processed))
print("Extracted {} events.".format(len(all_events)))
# Print out the events
for event in sorted(all_events, key=lambda e: e[0]):
print("{} - {}".format(event[1],event[2]))
Let’s look at the results: With the simple patterns we were already able to extract 48 events. While this is not too bad there are certainly many events missing. We would now need to go back to our regexes and refine them. Refine the pattern for single dates (maybe we should use a library for that) but also the patterns for sentences that describe an event. You can imagine that is is rather cumbersome.
extract_all_events(text,extract_events_regex)
RESULT: Processed: 0 Processed: 100 Processed: 200 Processed: 300 Processed: 400 Processed: 500 Processed: 600 Processed: 700 Extracted 48 events. 718 - Charles Martel waged war against the Saxons in support of the Neustrians 743 - his son Carloman in his role as Mayor of the Palace renewed the war against the Saxons, who had allied with and aided the duke Odilo of Bavaria 751 - Pippin III, Mayor of the Palace under the Merovingian king, himself assumed the title of king and was anointed by the Church 936 - Otto I was crowned German king at Aachen, in 961 King of Italy in Pavia and crowned emperor by Pope John XII in Rome in 962 1122 - a temporary reconciliation was reached between Henry V and the Pope with the Concordat of Worms 1137 - the prince-electors turned back to the Hohenstaufen family for a candidate, Conrad III 1180 - Henry the Lion was outlawed, Saxony was divided, and Bavaria was given to Otto of Wittelsbach, who founded the Wittelsbach dynasty, which was to rule Bavaria until 1918 1230 - the Catholic monastic order of the Teutonic Knights launched the Prussian Crusade ...
Second Attempt: Use Named Entity Recognition and Dependency Parsing
I hope you are convinced that designing regular expressions to capture a wide range of sentences that signify an event would mean a lot of effort. In order to save us the effort we can use a technique from Natural Language Processing that is called Named Entity Recognition (NER). Named Entity Recognition amounts to annotating phrases in a text that are not “regular” words but instead refer to some specific entity in the real word. For example the following text contains named entities such as :
- the Western Roman Empire,
- the 5th century, or
- the Franks
Note especially the second example (the 5th century), these are the kind of named entities we are interested in: dates.
For this article, we use spaCy, a library for performing different kinds of NLP tasks, among them named entity recognition. Let’s load spaCy and perform NER on the sentence from above. We print out all found named entities together with their label, that is the type of named entity.
nlp = spacy.load("en_core_web_sm")
doc = nlp("After the fall of the Western Roman Empire in the 5th century, the Franks, like other post-Roman Western Europeans, emerged as a tribal confederacy in the Middle Rhine-Weser region, among the territory soon to be called Austrasia (the 'eastern land'), the northeastern portion of the future Kingdom of the Merovingian Franks.")
for ent in doc.ents:
print("{} -> {}".format(ent.text,ent.label_))
RESULT: the Western Roman Empire -> LOC the 5th century -> DATE Franks -> PERSON Western Europeans -> NORP the Middle Rhine-Weser -> LOC Austrasia -> GPE Kingdom -> GPE the Merovingian Franks -> ORG
If we apply NER to our original text we see that there is a whole range of dates in many different formats.
doc = nlp(text) for ent in filter(lambda e: e.label_=='DATE',doc.ents): print(ent.text)
RESULT: 1907 at least 600,000 years Between 1994 and 1998 1856 around 40,000 years old 1858 1864 1988 3rd century the 1st century ...
At this point we have to extract the actual events from the named entities relating to dates that we found. We could go the easy route and simply take the whole sentence containting the date. I want to make it a bit more interesting and extract only the core of the sentence that describes the event. For this we use another NLP technique called dependency parsing. This techniques reconstructs the grammatical structure from a text.
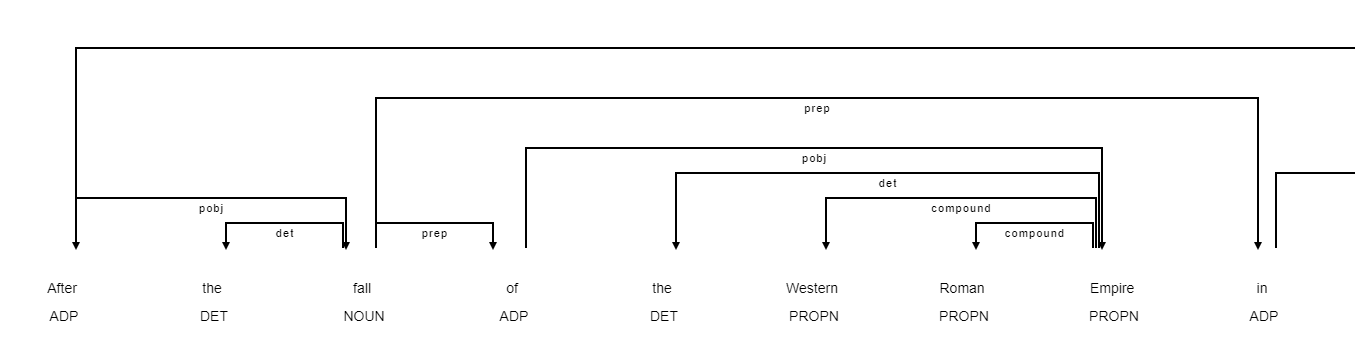
Let’s look at an example to see how it works. You see that the words are connected via arcs. Earch arc posseses a label that describes the relation between the words. Unluckily, the labels of the arcs are not shown in the colab version. Together, the arcs form a tree. In the example, the root of the tree is at the word “emerged”.
doc = nlp("After the fall of the Western Roman Empire in the 5th century, the Franks, like other post-Roman Western Europeans, emerged as a tribal confederacy in the Middle Rhine-Weser region, among the territory soon to be called Austrasia (the 'eastern land'), the northeastern portion of the future Kingdom of the Merovingian Franks.")
IPython.display.HTML(spacy.displacy.render(doc,style="dep", page=True, options={"compact":True}))
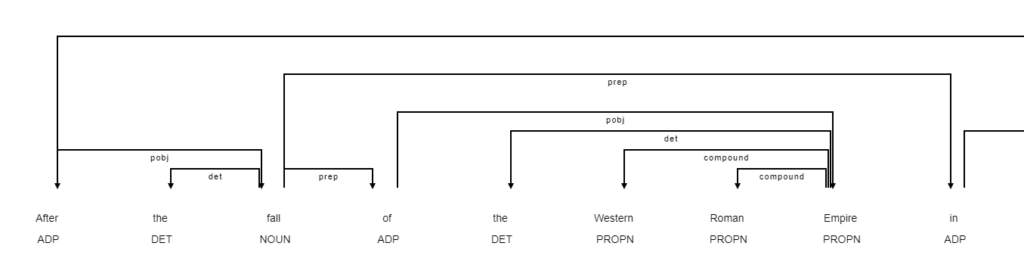
We will use the dependency structure to extract only a part of the text. The idea is to start from the detected date and walk up the tree until we are at the root (there may be more than one root, if the current line contains more sentences). When we are at the root we select a couple of subtrees and build a new text from that. Often, the root will be a verb. In this case we will e.g. select the subject and the object and use this as a summarization of the sentence. It is a rather simple approach but is good enough to get the idea.
def dep_subtree(token, dep):
deps =[child.dep_ for child in token.children]
child=next(filter(lambda c: c.dep_==dep, token.children), None)
if child != None:
return " ".join([c.text for c in child.subtree])
else:
return ""
# to remove citations, e.g. "[91]" as this makes problems with spaCy
p = re.compile(r'\[\d+\]')
def extract_events_spacy(line):
line=p.sub('', line)
events = []
doc = nlp(line)
for ent in filter(lambda e: e.label_=='DATE',doc.ents):
try:
start,end = parse(ent.text)
except:
# could not parse the dates, hence ignore it
continue
current = ent.root
while current.dep_ != "ROOT":
current = current.head
desc = " ".join(filter(None,[
dep_subtree(current,"nsubj"),
dep_subtree(current,"nsubjpass"),
dep_subtree(current,"auxpass"),
dep_subtree(current,"amod"),
dep_subtree(current,"det"),
current.text,
dep_subtree(current,"acl"),
dep_subtree(current,"dobj"),
dep_subtree(current,"attr"),
dep_subtree(current,"advmod")]))
events = events + [(start,ent.text,desc)]
return events
Let’s look at an example to see how this works out:
extract_events_spacy("The Protestant Reformation was the first successful challenge to the Catholic Church and began in 1521 as Luther was outlawed at the Diet of Worms after his refusal to repent. ")
RESULT: [(datetime.datetime(1521, 1, 1, 0, 0), '1521', 'The Protestant Reformation was the first successful challenge to the Catholic Church')]
All we have to do to get our (hopefully) improved timeline is use our new extraction function on the whole text
extract_all_events(text,extract_events_spacy)
RESULT: Processed: 0 Processed: 100 Processed: 200 Processed: 300 Processed: 400 Processed: 500 Processed: 600 Processed: 700 Extracted 446 events. 1027–1125 - The Salian emperors ( reigned 1027–1125 ) retained the stem duchies 1039 to 1056 - the empire supported the Cluniac reforms of the Church , the Peace of God , prohibition of simony ( the purchase of clerical offices ) 1056 - Total population estimates of the German territories range around 5 to 6 million 1077 - The subsequent conflict in which emperor Henry IV was compelled to submit to the Pope at Canossa in 1077 , after having been excommunicated came 1111 - Henry V ( 1086–1125 ) , great - grandson of Conrad II , who had overthrown his father Henry IV became Holy Roman Emperor 1122 - a temporary reconciliation was reached 1135 - Emperor Lothair II re - established sovereignty 1137 - the prince - electors turned back to the Hohenstaufen family 1155 to 1190 - Friedrich Barbarossa was Holy Roman Emperor ...
TL;DR
Extracting events from text, such as news articles, socical media content, reports, etc. is useful to gather data in order to run analyses, make predictions or inform decisions. There are sophisticated techniques around, but you can get some good results with simple techniques, too. This article looked at two methods to extract a timeline from a text. We started with a simple approach based on regular expressions. We saw that fine-tuning the regular expressions is cumbersome and therefore we swithed to an approach using named entity recognition (NER). With NER we can recognize different types of dates out of the box. We then used dependency parsing to build an extract of the event. Here is how the results looks like:
| Date | Event |
|---|---|
| 1027–1125 | The Salian emperors ( reigned 1027–1125 ) retained the stem duchies |
| 1039 to 1056 | the empire supported the Cluniac reforms of the Church , the Peace of God , prohibition of simony ( the purchase of clerical offices ) |
| 1056 | Total population estimates of the German territories range around 5 to 6 million |


